熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區沙井街道后亭茅洲山工業園工業大廈全至科技創新園科創大廈2層2A


卷積核作為卷積神經網絡的基本組成,其直接影響了網絡的性能。選擇合適的卷積核可以讓模型更高效,或者是提高模型的精度。本文介紹了近年來主要的卷積核類型,這里首先我們需要解釋一下CNN中廣泛使用的卷積運算是一個誤稱。嚴格地說,所使用的運算是相關(Correlation)運算,而不是卷積(Convolution)運算。先分別理解這兩個運算符的細微差別。
1.Convolution VsCorrelation
1.1相關 (Correlation)
相關是在圖像上移動一個通常被稱為核的濾波器,并計算每個位置的乘積之和的過程。換句話說,相關運算的第一個值對應于濾波器的零位移,第二個值對應于位移的一個單位,依此類推。
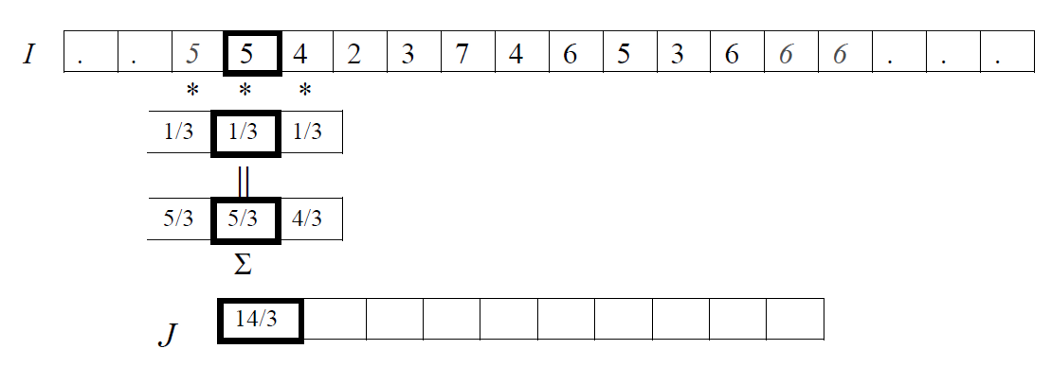
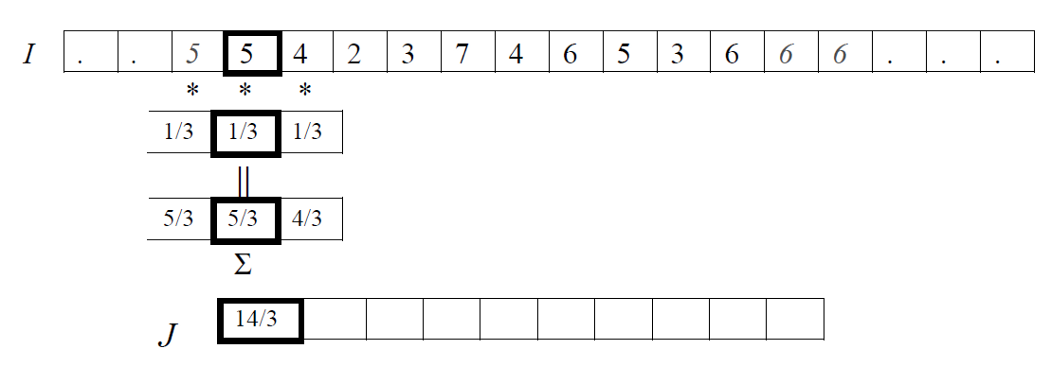
如下公式給出了使用濾波器 F 對輸入數據 I 進行一維相關運算的數學公式。我們假設 F 有奇數個元素,所以當它移動時,它的中心就在圖像 I 的一個元素上。所以我們說 F 有2N+1個元素,這些元素從-N索引到N,所以F的中心元素是F(0)。
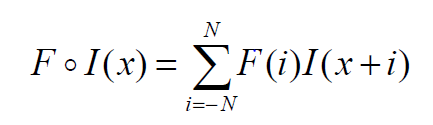
類似地,我們可以將這個概念擴展到二維,如下。基本思想是一樣的,除了圖像和濾波器現在是二維的,可以假設濾波器有奇數個元素,所以它用(2N+1)x(2N+1)矩陣表示。
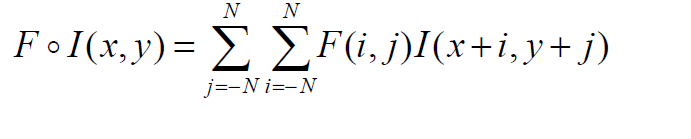
二維中的相關運算非常直接。我們只需取一個給定大小的濾波器,并將其放置在圖像中與濾波器大小相同的局部區域上,然后滑動繼續進行同樣的操作。這樣的操作具有兩個特性:
· 平移不變性:視覺系統能夠感知到同一個物體,而不管它出現在圖像中的什么位置。
· 局部感知性:視覺系統專注于局部區域,而不考慮圖像的其他部分發生了什么。
1.2卷積(Convolution)
卷積運算與互相關運算非常相似,但略有不同。在卷積運算中,核先翻轉180度,然后應用于圖像。數學公式如下:
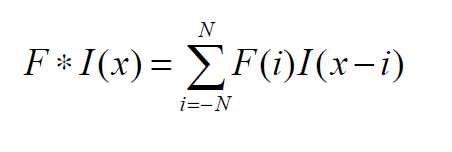
在二維卷積的情況下,我們水平和垂直翻轉濾波器。這可以寫成:
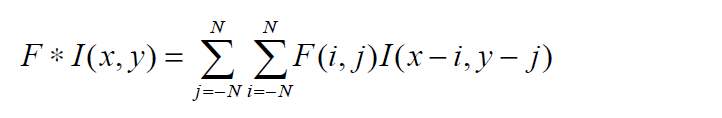
卷積運算同樣具有平移不變性和局部感知性的性質。
需要申明的是:
· 神經網絡中的卷積其實是數學上的相關運算;
· 本文接下來出現的卷積,從數學上看都是相關運算。
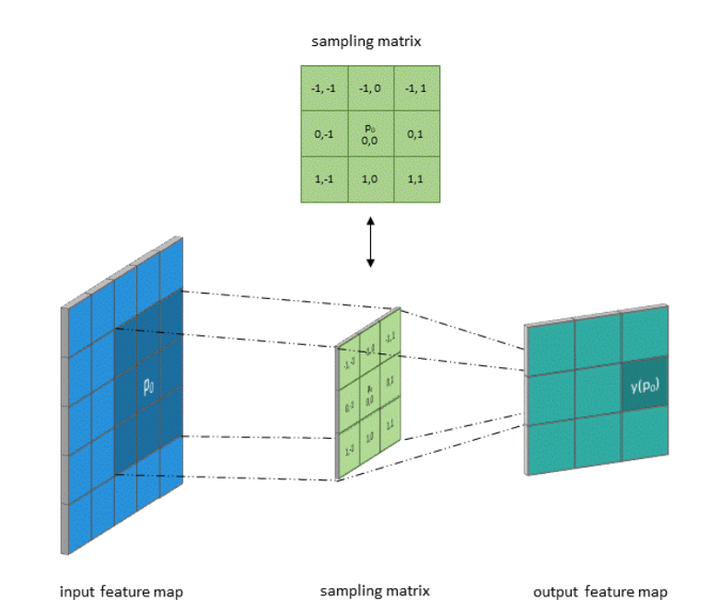
1.3卷積和采樣矩陣
標準卷積可以看作在圖像上應用采樣矩陣(Sampling Matrix)來加權輸入的樣本,如下圖所示,使用的卷積核大小為3、步長為1且沒有填充的采樣矩陣。
1.4卷積的參數
· Kernel size: 定義卷積核的大小,影響卷積操作的感受野,一般使用3x3,5x5 等
· Stride: 定義遍歷圖像時卷積核移動的步長
· Channel: 定義卷積運算的輸入和輸出通道數
· Padding: 定義如何處理樣本邊界的方式,分為不填充或者對邊界填充0,不填充的只對特征圖做卷積操作,會使得輸出的特征圖小于輸入的特征圖;對邊界填充0,可以使得輸入和輸出的特征圖保持一致
2.千變萬化的卷積
常見的卷積類型有很多,根據其操作的區域大致可以分為兩類:通道相關性、空間相關性。
· 通道相關性的卷積核改變了卷積在channel維度操作,如:Group Convolution、Depthwise Separable Convolutions;
· 空間相關性的卷積核是改變了卷積在w,h維度的操作。除了這兩類近年來也出現了一些新的改進思路:如動態卷積,異構卷積。
2.1通道相關(channel)
Group Convolution
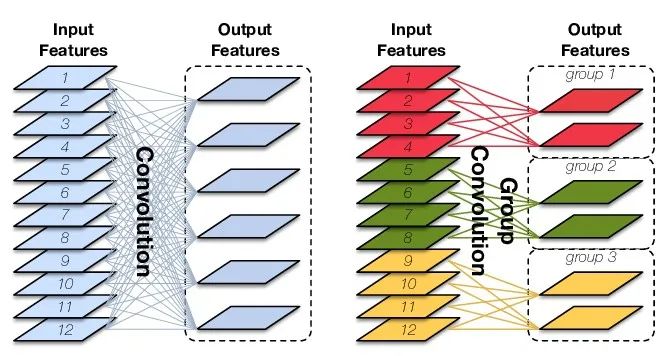
Group Convolution(分組卷積)就是對輸入feature map在channel維度進行分組,然后每組分別卷積。
假設輸入featuremap的尺寸仍為C?H?W,輸出feature map的數量為N個,如果設定要分成G個groups,則每組的輸入feature map數量為C/G,每組的輸出feature map數量為N/G,每個卷積核的尺寸為C/G?K?K,卷積核的總數仍為N個,每組的卷積核數量為N/G,卷積核只與其同組的輸入feature map進行卷積,卷積核的總參數量為N?C/G?K?K,可見,總參數量減少為原來的1/G。其連接方式如下圖右所示,group1輸出map數為2,有2個卷積核,每個卷積核的channel數為4,與group1的輸入map的channel數相同,卷積核只與同組的輸入map卷積,而不與其他組的輸入map卷積。
· Depthwise Convolution
當分組數量等于輸入map數量,輸出map數量也等于輸入map數量,即G=C=N、N個卷積核每個尺寸為1?K?K時,Group Convolution就成了Depthwise Convolution(深度卷積)。
· Global Depthwise Convolution
更進一步,如果分組數G=N=C,同時卷積核的尺寸與輸入map的尺寸相同,即K=H=W,則輸出map為 C?1?1 即長度為 C 的向量,此時稱之為GlobalDepthwise Convolution(GDC),與GlobalAverage Pooling(GAP)的不同之處在于,GDC給每個位置賦予了可學習的權重。
· Shuffled Grouped Convolution
Shuffled GroupedConvolutions 是在 Groupconvolution 計算后對輸出的 output feature maps 進行shuffle(打亂)處理,以使得接下來的Group convolutionfilters可在每個group所輸出的部分channels構成的集合上進行計算。其操作如下圖所示,這么做的原因是為了有效地減小Groups convolution使用導致的Groups間特征互不相通的負面影響。

Depthwise SeparableConvolution
Depthwise SeparableConvolutions(深度可分離卷積) 是由 Depthwise Separable Convolution是將一個完整的卷積運算分解為兩步進行,即Depthwise Convolution與Pointwise Convolution。
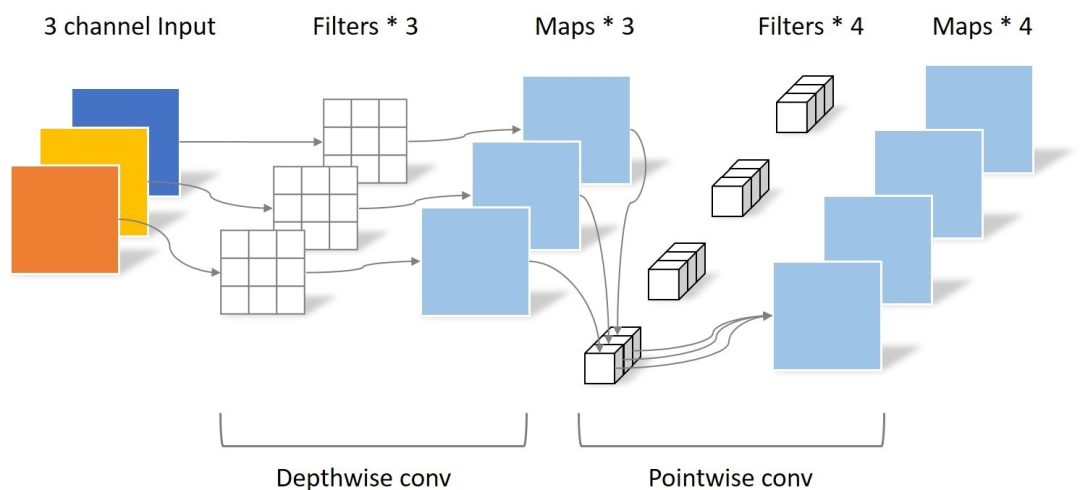
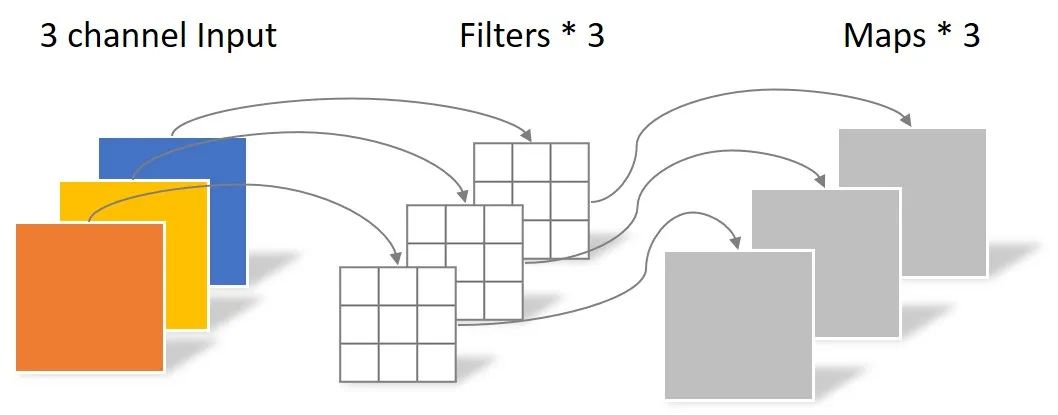
Depthwise Convolution
Depthwise Convolution完成后的Feature map數量與輸入層的通道數相同,無法擴展Feature map。而且這種運算對輸入層的每個通道獨立進行卷積運算,沒有有效的利用不同通道在相同空間位置上的feature信息。因此需要Pointwise Convolution來將這些Feature map進行組合生成新的Feature map。
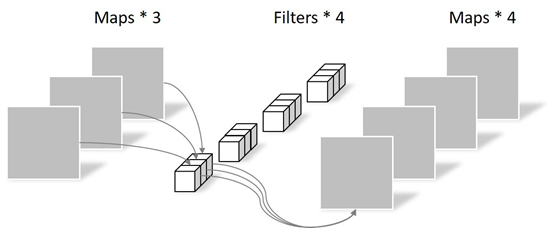
Pointwise Convolution
Pointwise Convolution的運算與常規卷積運算非常相似,它的卷積核的尺寸為 1×1×M,M為上一層的通道數。所以這里的卷積運算會將上一步的map在深度方向上進行加權組合,生成新的Feature map。有幾個卷積核就有幾個輸出Feature map。
Depthwise SeparableConvolution的參數個數大約是常規卷積的1/3。因此,在參數量相同的前提下,采用Depthwise SeparableConvolution的神經網絡層數可以做得更深。
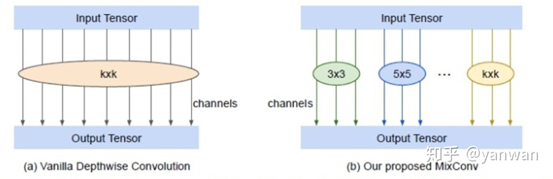
MixConv
MixConv將不同尺度的卷積核融合到一個單獨的卷積操作,使其可以易于獲取具有多個分辨率的不同模式。如下圖是MixConv的結構,將通道分成了多個組,對每個通道組應用不同尺寸的卷積核。作者將其MixConv表示為普通深度卷積的一個簡單替換,但可以在ImageNet分類和COCO目標檢測上顯著地提高MobileNets的準確性和效率。
2.2空間相關(Spatial)
Dilated Convolution
Dilated Convolution 就是在常規卷積中引入一個 dilationrate 參數也就是指的是kernel的間隔數量(正常的convolution 是dilatation rate 1)。從下面的動圖就可以很好理解了:
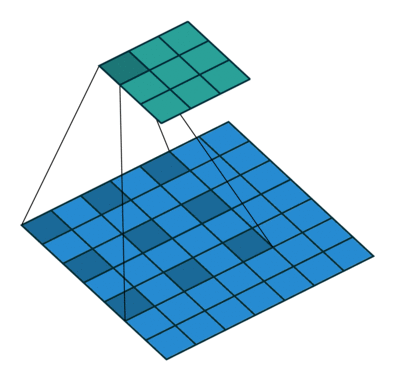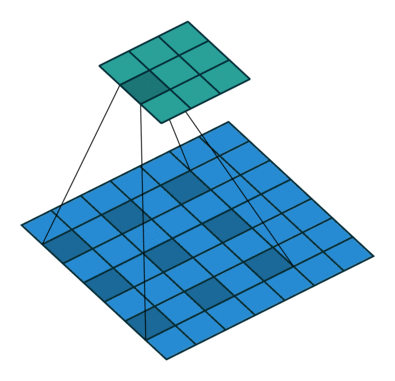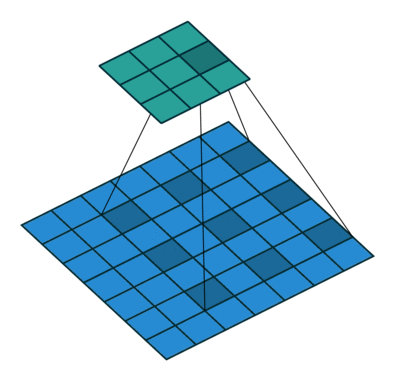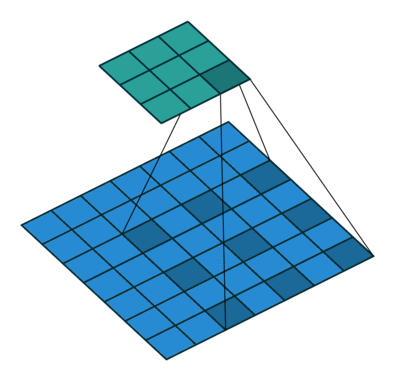
Dilated Convolution
kernel: 3x3, Pading: 0,dilationrate: 2
Dilated Convolutions可以在參數量不變的情況下有效的提高卷積核的感受野。DilatedConvolutions主要應用于圖像分割領域,這是由于其可以替代up-sampling和 pooling layer。up-sampling 和 pooling layer會導致內部數據結構丟失;空間層級化信息丟失。
小物體信息無法重建 (假設有四個pooling layer 則 任何小于 2^4 = 16 pixel 的物體信息將理論上無法重建。)在這樣問題的存在下,語義分割問題一直處在瓶頸期無法再明顯提高精度,而 dilated convolution 的設計就良好地避免了這些問題。
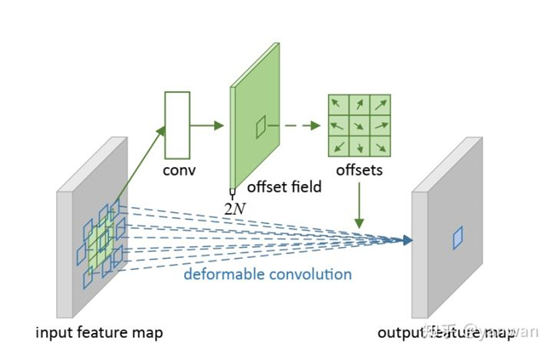
DeformableConvolution
(1) DCN v1
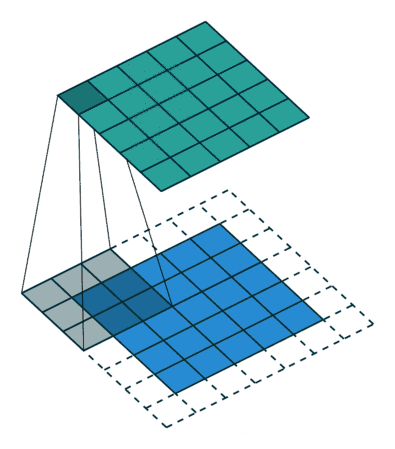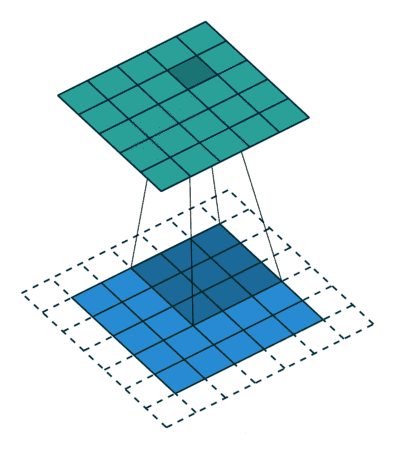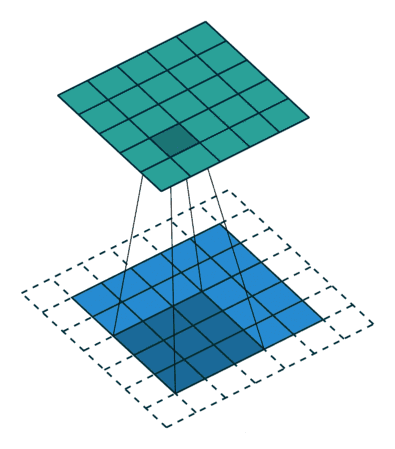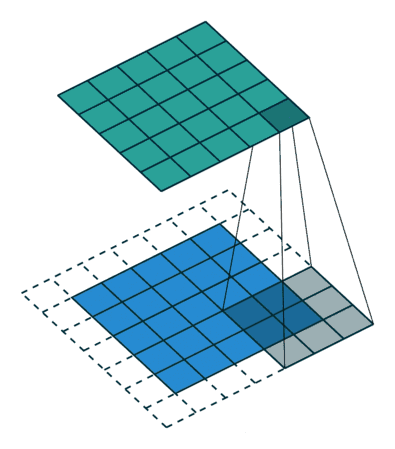
可變形卷積引入了可變形模塊的機制,它具有可學習的形狀以適應特征的變化。傳統上,卷積中由采樣矩陣定義的核形狀從一開始就是固定的。
可變形卷積使的采樣矩陣具有可學習性,允許核的形狀適應輸入中未知的復雜物體。讓我們看看下圖來理解這個概念。
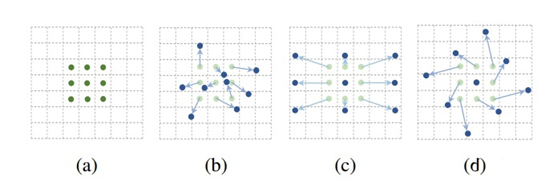
如上圖3×3標準卷積和可變形卷積中采樣矩陣地圖示:
· a 是標準卷積的采樣矩陣(綠點);
· b是變形卷積中偏移量增大(淺藍色箭頭)的變形采樣位置(深藍色點);
· c 和 d 是 b 的特例,表明可變形卷積推廣了尺度、(各向異性)縱橫比和旋轉的各種變換;
可變形卷積學習是具有位置偏移的采樣矩陣,而不像標準卷積那樣使用固定偏移的采樣矩陣。偏移量通過附加的卷積層從前面的特征映射中學習。如果將標準卷積表示為:
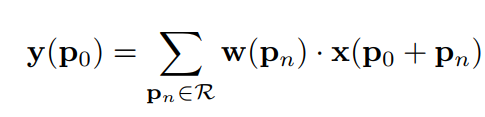
那么可變形卷積可以表示為:
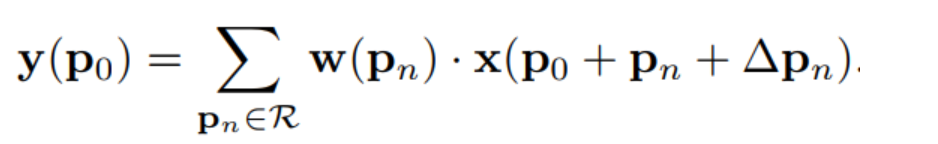
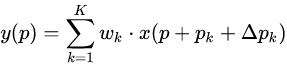
式中,Δp?表示加入正常卷積運算的偏移量。p?是枚舉采樣點。現在采樣點位于不規則的偏移位置p?+?p?,即核的采樣位置重新分布,不再是規則矩形,允許采樣點擴散成非gird形狀。
如下所示,偏移量通過在輸入特征映射上應用卷積層來獲得。假設原來的卷積操作是3*3的,那么為了學習offsets,需要定義另外一個3*3的卷積層,輸出的offset field其實就是原來feature map大小,channel數等于2N(分別表示x,y方向的偏移,這里的N實際上是 kernel 里的 samplinglocation數。如果 3 x 3 的 kernel 的話,N = 9)。這樣的話,有了輸入的feature map,有了和feature map一樣大小的offset field,我們就可以進行deformable卷積運算。所有的參數都可以通過反向傳播學習得到。
(2) DCN v2
DCN v1的問題是:可變形卷積有可能引入了無用的區域來干擾我們的特征提取,降低了算法的表現,如下圖所示。


因此,在DCNv1的offset基礎上,添加每個采樣點的權重,如下:
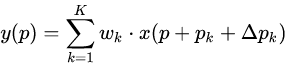
其中,Δp?是偏移量,Δm學到的權重。這樣的好處是增加了更大的自由度,對于某些不想要的采樣點權重可以學成0。
總的來說,DCNv1中引入的偏移量是要尋找有效信息的區域位置,DCN v2中引入權重系數是要給找到的這個位置賦予權重,這兩方面保證了有效信息的準確提取。
Spatially SeparableConvolutions
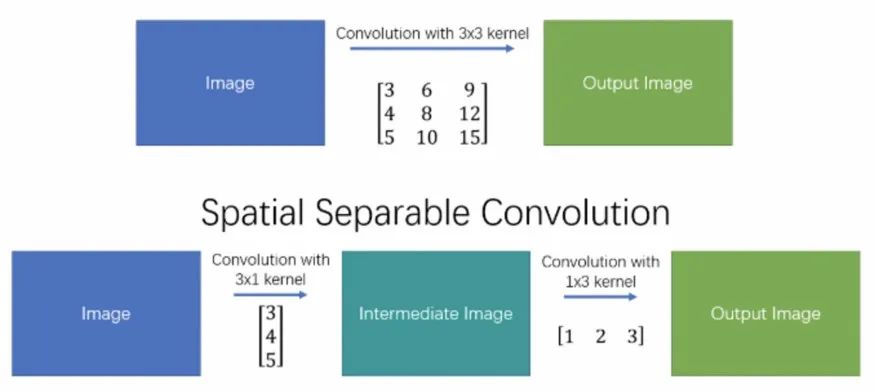
SpatiallySeparableConvolutions將卷積分成兩部分,最常見的是把3x3的kernel分解成3x1和1x3的kernel。例如:
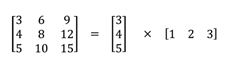
通過這種方式,原本一次卷積要算9次乘法,現在只需要6次。但是SpatiallySeparableConvolutions 有一個缺陷那就是并不是所有卷積核可以分成兩個小的卷積核。
FlattenedConvolutions
Flattened Convolutions是將三維卷積核拆分成3個1維卷積核。Flattened Convolutions 計算過程如圖(b)。
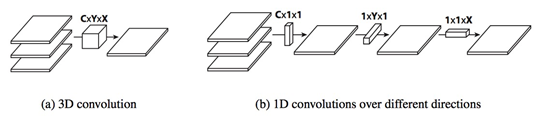
Flattened Convolutions 極大地減少了計算量。FlattenedConvolutions 引入了的不對稱卷積,再后來也證實了這種不對稱卷積Nx1和1xN,對準確率是有提升的。
2.3新的卷積思路
HetConv 異構卷積
HetConv 是在2019年CVPR提出的一種新的高效卷積方式,它在CIFAR10、ImageNet等數據集超過了標準卷積以及DW+PW的高效卷積組合形式,取得了更高的分類性能。HetConv 主要側重于設計新的卷積核,傳統的卷積和按文中說法稱為同構卷積(homogeneousconvolution),即該過濾器包含的所有卷積核都是同樣大小(比如在 3 × 3 × 256CONV2D 過濾器中,所有 256 個核都是 3×3 大小),HetConv 是異構卷積(heterogeneous convolution), 即過濾器包含不同大小的卷積核(比如在某個 HetCOnv 過濾器中,256 核有的是 3×3 大小,其余的是 1×1 大小,由參數P控制 1×1 卷積核的數量)。
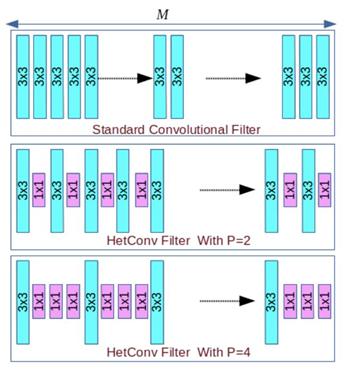
HetConv在ResNet 和 VGG-16 等不同架構上進行了廣泛的實驗——只是將它們的原始過濾器替換成了HetConv。實驗發現,無需犧牲這些模型的準確度就能大幅降低 FLOPs(3 到 8 倍)。
Dynamic Convolution動態卷積
Dynamic Convolution是微軟AI在CVPR2020提出的高性能漲點的動態卷積。動態卷積這種新的設計能夠在不增加網絡深度或寬度的情況下增加模型的表達能力(representation capacity)。動態卷積的基本思路就是根據輸入圖像,自適應地調整卷積參數。如圖1所示,靜態卷積用同一個卷積核對所有的輸入圖像做相同的操作,而動態卷積會對不同的圖像(如汽車、馬、花)做出調整,用更適合的卷積參數進行處理。簡單地來說,卷積核是輸入的函數。

動態卷積沒有在每層上使用單個卷積核,而是根據注意力動態地聚合多個并行卷積核。注意力會根據輸入動態地調整每個卷積核的權重,從而生成自適應的動態卷積。由于注意力是輸入的函數,動態卷積不再是一個線性函數。通過注意力以非線性方式疊加卷積核具有更強的表示能力。
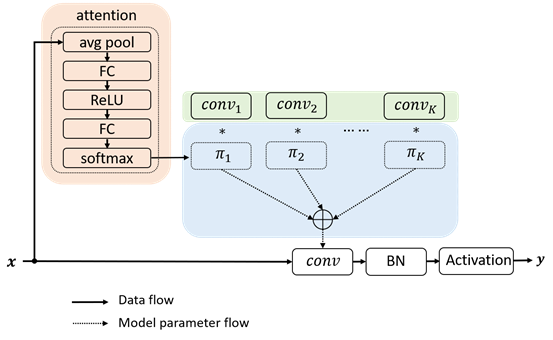
動態卷積可以輕易地嵌入替換現有網絡架構的卷積,比如1×1卷積, 3×3卷積,組卷積以及深度卷積。實驗表明,動態卷積在 ImageNet 分類和 COCO 關鍵點檢測兩個視覺任務上均具有顯著的提升。例如,通過在 SOTA 架構 Mobilenet 上簡單地使用動態卷積,ImageNet 分類的 top-1 準確度提高了 2.3%,而FLOP 僅增加了 4%,在 COCO 關鍵點檢測上實現了 2.9 的 AP 增益。在關鍵點檢測上,動態卷積在 backbone 和 head 上同樣有效。
3.總結
卷積核作為卷積神經網絡的基礎部分,它的直接影響了神經網絡的性能。本文按照卷積核改進思路分為通道相關性和空間相關性,并介紹了近年來主要的卷積方式。新的卷積核提出主要由兩種出發點:模型輕量化,在盡量保持模型精度的情況下,減小模型的參數和計算;高精度模型,在盡量不增加模型的計算和參數下,有效的提高模型的精度。簡單來說,
· 模型輕量化的有:group/depthwiseconv等,
· 高精度模型的有deformableconv,動態卷積等。
熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區沙井街道后亭茅洲山工業園工業大廈全至科技創新園科創大廈2層2A
